Comparing the characteristics of SLMs to LLMs for digital transformation projects.
Small language models (SLMs) can perform better than large language models (LLMs). This counterintuitive idea applies to many engineering applications because many artificial intelligence (AI) applications don’t require an LLM. We often assume that more information technology capacity is better for search, data analytics and digital transformation.
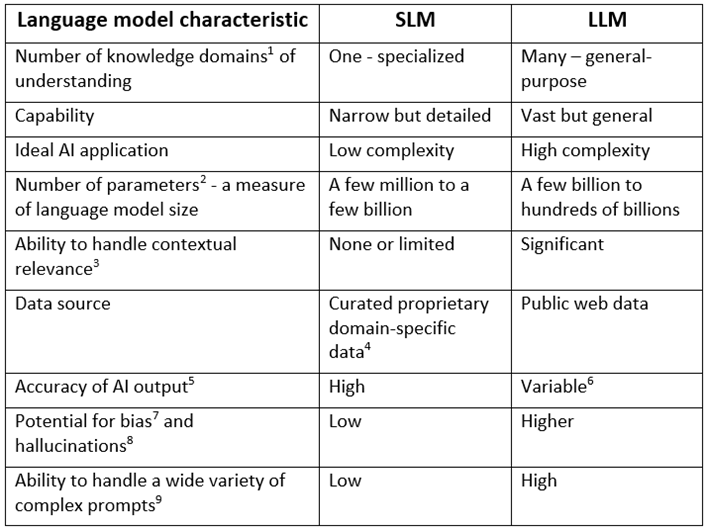
SLMs offer numerous advantages for small, specialized AI applications, such as digital transformation. LLMs are more effective for large, general-purpose AI applications.
Let’s compare the characteristics of SLMs to LLMs for digital transformation projects.
SLM vs. LLM focus
SLMs are efficient, domain-specific AI models optimized for tasks that can run on smaller devices using limited resources. LLMs are powerful, general-purpose AI models that excel at complex tasks but require substantial computing resources.
SLMs are explicitly designed for small domain-specific tasks, such as digital transformation, which is critical to the work of engineers. SLMs offer high accuracy for niche AI applications. LLMs, on the other hand, are trained on enormous datasets to enable them to respond to a wide range of general-purpose tasks. LLMs sacrifice accuracy and efficiency to achieve general applicability.
Comparing language model characteristics
SLMs are quite different from LLMs, despite their similar names. Engineers can use these language model characteristics to determine which language model best fits the characteristics of their digital transformation project.
Considering data privacy support
Data privacy is a significant issue for digital transformation projects because the internal data being transformed often contains intellectual property that underlies the company’s competitive advantage.
Support for data privacy depends on where the SLM or LLM is deployed. If the AI model is deployed on-premise, data privacy can be high if appropriate cybersecurity defences are in place. If the SLM or LLM is deployed in a cloud data centre, data privacy varies depending on the terms of the cloud service agreement. Some AI service vendors state that all end-user prompts will be used to train their AI model further. Other vendors commit to not using the provided data. If engineers are unsure that the vendor can meet its stated data privacy practices or if those practices are unacceptable, then implementing the AI application on-premises is the only course of action.
SLMs offer many advantages for digital transformation projects because these projects use domain-specific data. LLMs are more effective for large, general-purpose AI applications that require vast data volumes. In the follow-on article, we’ll discuss the differences between SLMs and LLMs for construction and operation.
Footnotes: AI Glossary
- Domain knowledge is knowledge of a specific discipline, such as engineering or digital transformation, in contrast to general knowledge.
- Parameters are the variables that the AI model learns during its training process.
- Contextual relevance is the ability of the AI model to understand the broader context of the prompt text to which it is responding.
- Curated proprietary domain-specific data is typically internal data to the organization. Internal data is often uneven or poor in quality. It is often a constraint on the value that AI applications based on an SLM can achieve. Improving this data quality will improve the value of AI applications.
- Accurate output is essential to building confidence and trust in the AI model.
- The accuracy of LLM output is undermined by the contradictions, ambiguity, incompleteness and deliberately false statements found in public web data. LLM AI output is better for English and Western societies because that’s where most of the web data originates.
- Bias refers to incidents of biased AI model output caused by human biases that skew the training data. The bias leads to distorted outputs and potentially harmful outcomes.
- Hallucinations are false or misleading AI model outputs that are presented as factual. They can mislead or embarrass. They occur when an AI model has been trained with insufficient or erroneous data.
- Prompts are the text that end-users provide to AI models to interpret and generate the requested output.



